


AI is everywhere in 2026. So are smarter tools. And hiring “A-players” is still a top priority. Yet margins don’t automatically improve, and time-to-market doesn’t magically compress.
Because execution is still chaotic.
Two symptoms show up in every CEO dashboard—whether you build software, run operations, or manage a multi-country business:
- Rework loops: the same issues repeat, teams fix symptoms, and you pay twice.
- Coordination tax: status meetings multiply because no one trusts the system of record.
If you feel “busy” but not “faster,” you don’t have an AI problem. You have a systems problem.
AI doesn’t transform companies—systems do. AI only amplifies the system you already have.
The Problem CEOs Keep Misdiagnosing
Most organizations treat transformation like a shopping list:
- Buy a tool.
- Hire a specialist.
- Run an “AI initiative.”
- Expect a step-change.
But tools don’t create outcomes. People do. And people don’t execute consistently without a shared operating model.
When execution lacks structure, AI becomes an accelerant for the wrong things:
- It helps you create more work (more docs, more drafts, more “ideas”).
- It doesn’t help you ship better outcomes (fewer defects, faster cycles, less rework).
The result is familiar:
- Higher spend: more SaaS subscriptions, more contractors, more consultants.
- Lower confidence: leaders don’t trust timelines, so they demand more updates.
- Slower delivery: not because teams are lazy—because work is constantly being re-decided.
And yes, talent suffers too. High performers don’t hate hard work. They hate avoidable chaos.
Why Tools and Talent Fail Without Systems (The Hidden ROI Leak)
Let’s call the real cost by its name: you are paying for execution twice.
Once for building the work. Then again for:
- Clarifying what was meant
- Fixing what broke
- Coordinating what should have been visible
This is where ROI disappears.
Rework Is the Most Expensive “Feature”
Rework is rarely tracked as rework. It hides under “bug fixes,” “polish,” “alignment,” or “quick tweaks.”
But at scale, rework becomes a tax on every sprint, every launch, every campaign.
And AI can easily increase rework if inputs are unclear. If the requirement is vague, AI will produce a confident-looking output that is still wrong—just faster.
Coordination Becomes Your Operating Model
When accountability is unclear, leaders compensate with meetings.
If you don’t have a system, the meeting becomes the system.
Atlassian’s research highlights how much time teams lose simply searching for answers—a symptom of fragmented knowledge and unclear execution paths.
Tool Sprawl Creates Context Switching (Not Capability)
If every department has its own tools, dashboards, formats, and “ways of working,” AI won’t unify that. It will mirror the fragmentation.
GitLab’s survey-driven insights point to the growing pressure to streamline toolchains because complexity creates friction and context switching.
AI Adoption Is Rising—But Trust Is a Constraint
AI usage is climbing fast in development workflows, but trust and quality concerns remain a drag on productivity.
The Stack Overflow Developer Survey reports a large share of respondents using or planning to use AI tools, with many professionals using them daily.
So the CEO takeaway is simple:
- Adoption ≠ outcomes
- Speed ≠ delivery
- Output ≠ impact
If your delivery depends on heroes, AI will just help you fail faster.
Define the Missing Ingredient: The Execution OS
In this article, “systems” means one thing:
Execution OS = SOPs + workflows + clear owners + SLAs + review cadence.
Not bureaucracy. Not documentation for its own sake. A lightweight operating system that makes outcomes repeatable.
You don’t need a perfect system. You need a consistent one.
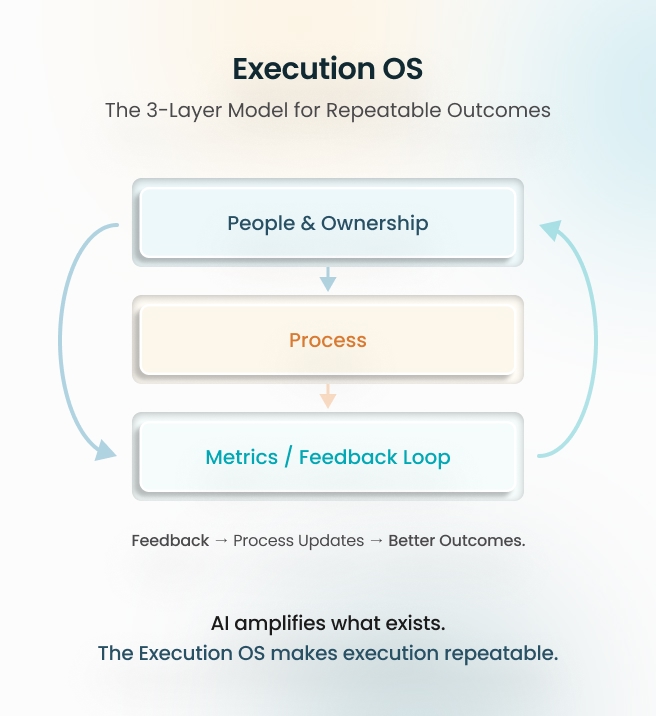
The 3-Layer System Model
If you want AI, tools, and talent to produce outcomes—not activity—install the Execution OS in three layers.
Layer 1: People / Ownership
This is where most transformations silently fail.
What you need is not “a team.” You need named owners for outcomes.
- One accountable owner per outcome (not per task)
- Clear decision rights (who can say “yes,” who can say “no”)
- Escalation rules (how fast decisions must be made)
CEO rule: If two people share ownership, no one owns it.
Stat placeholder: Teams with clearer ownership reduce decision latency and status meetings. [Source: Atlassian State of Teams 2025]
Layer 2: Process
Process is the bridge between intent and execution.
Your process must make four things visible:
- Intake quality (what are we building, why, and what “done” means)
- Dependencies (design/content/API/legal/security—owned, dated, tracked)
- Quality gates (definition of done, QA entry/exit criteria, release readiness)
- Change control (what happens when stakeholders change their mind late)
This is where “AI pilots” die in the real world—because no one designed the work to be executed consistently.
Stat placeholder: Toolchain complexity and context switching are consistent friction points in delivery. [Source: GitLab Global DevSecOps Survey 2024]
Layer 3: Metrics / Feedback Loops
If you don’t close the loop, you don’t have a system. You have a ritual. You need metrics that measure delivery health, not opinions.
Use a small set:
- Lead time (idea → production)
- Deployment frequency (how often you ship)
- Change failure rate (what breaks when you ship)
- Time to restore service (how fast you recover)
These “DORA metrics” are widely used because they connect execution quality to business outcomes and reliability.
Stat placeholder: DORA research consistently connects healthy delivery practices with both throughput and stability. [Source: DORA / Google Cloud DevOps Research 2024]
Mini-Case: Web/App Delivery That Stopped Relying on Heroics
This is a pattern I’ve seen repeatedly in web and app delivery—high capability, high effort, inconsistent outcomes.
The Situation (Before)
We had strong developers, modern stacks, and plenty of tools. Yet releases felt unpredictable and expensive.
Three recurring failure modes caused most of the pain:
- Last-minute stakeholder changes
“Small” changes arrived late, after sprint planning, and forced rework across design/dev/QA. - Dependency delays (design/content/API)
Teams started execution without dependency clarity. Work sat blocked. The sprint didn’t fail loudly—it leaked time quietly. - “Works on my machine” environment mismatch
Builds behaved differently across dev/stage/prod. QA cycles stretched. Releases became stressful.
The CEO-visible impact: more status meetings, more escalations, and less confidence in timelines.
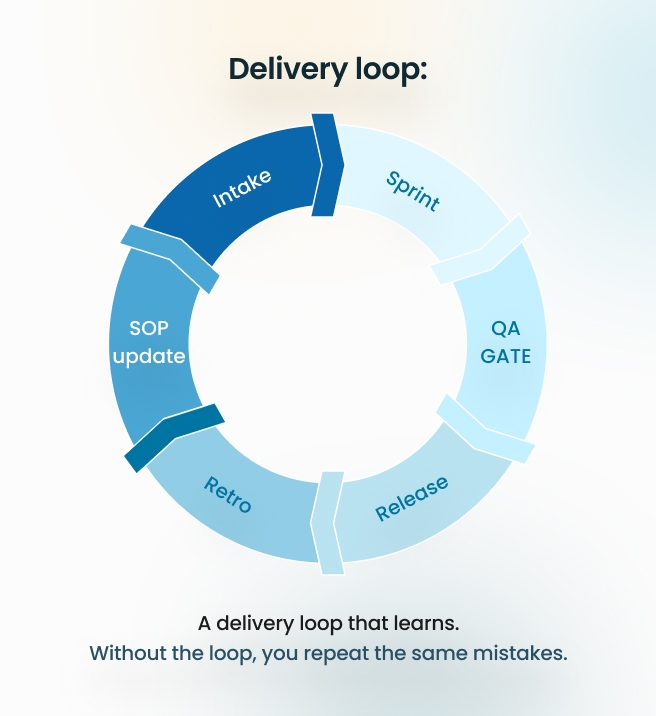
The Fix (Installing the Execution OS)
We didn’t buy another tool. We installed a delivery operating system.
1) Change-control rules
- Any late change becomes a change request (not a casual message)
- Owner approves trade-offs: scope, time, or quality—pick two
- Late changes roll into the next sprint unless they meet a defined “urgent” threshold
2) Dependency mapping with owners
- Every sprint backlog item must list upstream dependencies
- Each dependency has a named owner and due date
- “Not ready” items don’t enter sprint (no more optimistic guessing)
3) Environment parity + pre-flight checks
- Standardized dev/stage/prod configurations
- The release checklist includes environment validation
- Basic “pre-flight” checks catch mismatch early, not during QA panic
The Outcome (After)
Rework dropped by ~30%—not because people worked harder, but because the system stopped creating repeatable failure.
Where AI Became Genuinely Useful (Only After the System)
Once the Execution OS existed, AI stopped being a toy and became a lever:
- Detect ambiguity before sprint start:
AI reviewed meeting notes and flagged missing acceptance criteria, unclear edge cases, and unstated assumptions—before they became QA defects.Stat placeholder: AI adoption is high, but quality depends on inputs and review discipline. [Source: Stack Overflow Developer Survey 2025]
- Turn notes into user stories + acceptance criteria:
AI converted raw discussions into structured stories, scenarios, and “definition of done” drafts—then the owner validated them. Result: faster planning, fewer “what did you mean?” loops.
AI didn’t replace leadership. It reduced friction because the system made inputs consistent.
Quick Cross-Industry Examples (Same System, Different Surface Area)
Retail / E-commerce
AI can generate product descriptions, automate merchandising, and optimize campaigns. But if pricing updates, inventory feeds, and promotion rules aren’t governed, you create customer-facing chaos—wrong offers, wrong landing pages, wrong reporting.
Execution OS move: ownership for “promo-to-site-to-ads” workflow + change-control + weekly audit cadence.
Healthcare
AI can assist triage, patient communications, and operational reporting. But without standardized intake, approvals, and compliance checkpoints, you create risk: inconsistent patient messaging, delayed approvals, and fragmented handoffs.
Execution OS move: SOPs for content approval + SLAs for response + audit trail + KPI review cadence.
SaaS / Tech services
AI can accelerate coding, testing drafts, and incident summaries. But without environment parity, definition of done, and post-release learning loops, you simply ship faster into instability.
Execution OS move: DORA-aligned metrics + QA gates + retros that produce process updates.

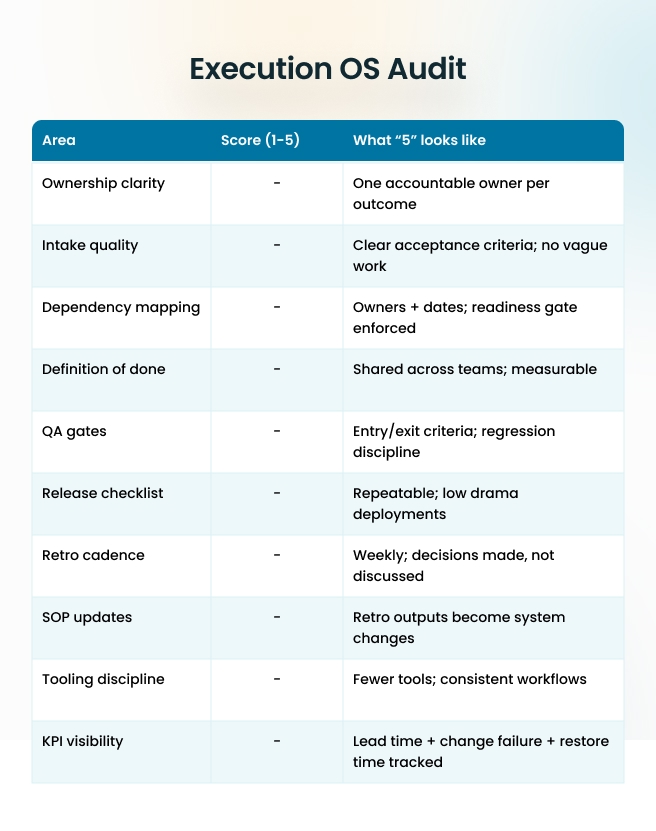
CEO Execution OS Checklist (10 Points)
- Name one accountable owner per outcome (not per task).
- Define “done” once: acceptance criteria + quality bar + release conditions.
- Standardize intake: one template, one source of truth.
- Make dependencies explicit: owner + due date + readiness gate.
- Install change-control: late change rules + trade-off decisions.
- Set SLAs for handoffs (design → dev → QA → release).
- Build environment parity: dev/stage/prod consistency + pre-flight checks.
- Run weekly delivery review: blockers, rework causes, decision latency.
- Run a retro that produces system updates (SOP/process changes).
- Add AI only where inputs are stable and review is defined (not everywhere).
Tight 30-Day Rollout Plan (Week 1–4)
Week 1: Ownership + Intake
CEO / COO: appoint the Execution OS owner for one pilot workflow (Intake → Sprint → QA → Release).
Owner: publish the intake template + “definition of done.”
Leads: pick one project/team as the pilot.
Deliverable: one-page “How work enters the system.”
Week 2: Process Gates + Dependencies
Owner: implement dependency mapping (owners + due dates).
Tech lead / PM: enforce readiness gate (not-ready items don’t enter sprint).
QA lead: define QA entry/exit criteria.
Deliverable: sprint board that shows dependencies visibly (not in chat).
Week 3: Change Control + Environment Parity
Owner + stakeholders: define late-change policy (urgent threshold + trade-offs).
Engineering: align dev/stage/prod configs + pre-flight checklist.
PM: install release checklist and calendar cadence.
Deliverable: release checklist + change request workflow.
Week 4: Metrics + Feedback Loop + AI Assist
Owner: start weekly delivery review and retro cadence.
Team: select 2 AI use-cases only:
- ambiguity detection before sprint
- notes → user stories + acceptance criteria
CEO: review early results: rework, cycle time, meeting load.
Deliverable: first “system update” shipped from retro (prove the loop works).
Conclusion
Stop Buying “More AI” and Start Installing the System It Needs
AI will not rescue an organization that can’t execute consistently. It will magnify whatever is already true—clarity or confusion, discipline or chaos, learning or repeating.
Install the Execution OS first: ownership, process, metrics, cadence. Then let AI amplify a stable foundation.
If you’re building an Execution OS in 2026 and want practical templates, checklists, and a simple 30-day rollout plan tailored to your org, fill out the form on this page. My team and I will review your inputs and share a structured starting point you can implement immediate.
Is Your AI Amplifying Chaos Or Clarity
Let’s Talk
FAQs
We’ve Invested Heavily in AI and Top Talent. Why Are Margins Still Compressing?
Because capability without structure compounds inefficiency. Rework, late-stage scope changes, and duplicated effort quietly erode margins. AI increases output, but without an Execution OS, it amplifies structural waste. This is where ZealousWeb steps in—to diagnose ownership gaps, process leakage, and weak feedback loops before further investment.
Every Major Initiative Feels Harder at Scale. What Are We Missing?
Scale exposes structural fragility. What works for 10 people breaks at 60 when ownership is unclear and dependencies lack readiness gates. Redesigning execution models ensures growth increases predictability instead of operational stress.
Timelines Slip Even When Teams Seem Aligned. Why?
Because alignment in meetings is not alignment in structure. If definitions of done, dependency ownership, and change-control policies are not enforced at the system level, execution drifts after agreement. Structural discipline turns verbal alignment into predictable delivery.
AI-Generated Work Still Requires Heavy Correction. Isn’t That Normal?
Some correction is normal. Systemic correction signals a structural issue. When inputs lack clear acceptance criteria or quality thresholds, AI amplifies ambiguity. Introducing process gates first—and embedding AI only where inputs and review standards are stable—significantly reduces correction overhead.
Our Best Performers Are Burning Out. What’s the Structural Cause?
Burnout usually signals system gaps, not talent issues. Repeated rework, unclear decision rights, and constant escalation waste effort and disengage high performers. Eliminating avoidable chaos restores leverage.
How Do We Know If We Are Hero-Dependent Instead of System-Dependent?
If outcomes vary based on who leads the work, you are hero-dependent. System-dependent organizations deliver repeatable results regardless of individual effort, which requires structured operating systems.
What Happens If We Scale AI Without Installing a System First?
You accelerate structural inefficiency. Instead of clarity, AI amplifies ambiguity—increasing rework and hidden costs. Installing an Execution OS first ensures AI scales on stable foundations.








