


Metrics Layer: Delivery Health, Not Activity Metrics
Activity metrics measure busyness. Delivery health metrics measure whether the system is working. We track using DORA metrics — lead time, deployment frequency, change failure rate, and mean time to recovery. When these are visible, decisions sharpen, problems surface early, and the improvement loop actually closes.
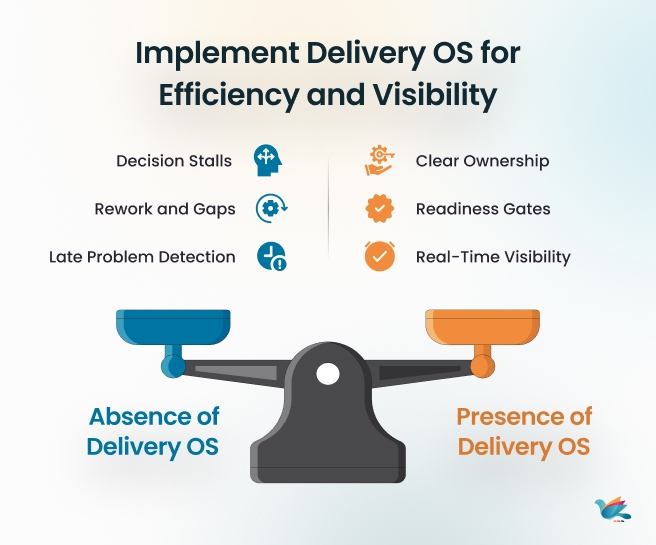
What Changes After Installing This System
The impact of a well-installed Execution OS isn’t felt in one dramatic moment. It accumulates — sprint over sprint, release over release — until the way work gets done looks fundamentally different from where it started. These are the four shifts organizations consistently experience:
Reduced Rework
- Defects stop recurring because the system removes the conditions that create them
- Acceptance criteria defined at intake means QA tests against reality, not interpretation
- Late-stage fixes drop significantly — not because teams work harder, but because the system stops generating avoidable failures
Lower Coordination Load
- Status meetings are reduced because the system of record is trusted
- Ownership clarity means fewer escalations and faster decisions
- Leaders spend less time chasing updates and more time making forward-looking calls
Predictable Delivery Cycles
- Sprint integrity holds because readiness gates and change-control are enforced
- Timelines become commitments, not estimates with silent disclaimers
- Stakeholder confidence in delivery increases — not because of better communication, but because of better execution
Calm, Scalable Execution
- Growth stops triggering operational stress
- New team members, new clients, and increased complexity are absorbed by the system — not by heroics
- The organization scales its output without scaling its chaos
Most organizations don’t fail because they lack capability. They fail because capability without structure doesn’t compound. This is what changes when the system is in place.

Conclusion
There’s a quiet moment every scaling organization eventually faces — when the sprints are running, the tools are live, the talent is in place, and delivery is still unpredictable. That moment isn’t a signal to add more. It’s a signal that the operating system underneath is missing. ZealousWeb exists for exactly that moment. We step in not as a vendor handing off deliverables, but as the architectural layer that makes everything already in motion finally work the way it was supposed to.
The execution infrastructure, the intelligence that turns data into decisions, the leadership clarity that replaces firefighting with forward momentum — this is what we design, install, and run. Because the goal was never just to deliver. It was always to build something that keeps delivering — long after the first sprint closes.
Is your delivery system built to scale — or built on heroics?
Start the Diagnostic Conversation








